
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 누적합
- 슬라이딩 윈도우
- spring
- 비트마스킹
- git
- 로그 수집
- HTTP/2
- 깃허브
- TwoPointer
- bitmasking
- HTTP/3
- RLD
- 스프링
- Domain Name Space
- 깃
- github
- SlidingWindow
- AppArmor
- 알고리즘
- 부팅 장애 대응
- 네트워크 관리 및 진단
- Linux
- Prefix sum
- tcp
- network
- 네트워크
- Spring Boot
- 리눅스
- 다이나믹 프로그래밍
- udp
- Today
- Total
kimgusxo 님의 블로그
맵(Map) 본문
1. 맵(Map)이란?
- 키(Key)와 값(Value)의 쌍을 저장하는 자료구조이다, 각각의 키는 유일(Unique)해야하며 키를 통해 대응하는 값을 빠르게 검색, 삽입, 삭제할 수 있다.
- 자바에서는 대표적으로 HashMap과 TreeMap을 사용하여 구현한다.
2. 해쉬맵(HashMap)

- 해쉬맵은 내부적으로 해시 함수를 사용하여 키를 해시 값으로 변환하고, 이를 기반으로 데이터를 저장하는 방식이다.
- 평균적으로 삽입/삭제/검색이 O(1)의 시간복잡도를 가진다.
- 해시 함수를 기반으로 데이터를 저장하기 때문에, 저장 순서와 검색 순서가 일치하지 않는다.
- 하나의 null 키와 여러 개의 null 값을 허용한다.
- 해시 버킷 배열에 키-값 쌍을 저장하며, 충돌시 체이닝을 사용한다.
2-1. 해쉬맵 주요 메소드
- put(K key, V value): 키와 값을 저장한다, 동일한 키가 이미 존재하면 기존 값을 새 값으로 대체하고 이전 값을 반환한다.
HashMap<String, Integer> hashMap = new HashMap<>();
hashMap.put("Apple", 3);
hashMap.put("Banana", 5);
hashMap.put("Cherry", 1);
- get(Object key): 주어진 키에 대응하는 값을 반환한다.
HashMap<String, Integer> hashMap = new HashMap<>();
hashMap.put("Apple", 3);
hashMap.put("Banana", 5);
hashMap.put("Cherry", 1);
System.out.println(hashMap.get("Apple")); // 출력: 3
- remove(Object key): 해당 키와 연결된 값을 삭제하고 삭제된 값을 반환한다.
HashMap<String, Integer> hashMap = new HashMap<>();
hashMap.put("Apple", 3);
hashMap.put("Banana", 5);
hashMap.put("Cherry", 1);
System.out.println(hashMap.remove("Banana")); // 출력: 5
- containsKey(Object key) / containsValue(Object value): 특정 키 또는 값이 Map에 존재하는지 확인한다.
HashMap<String, Integer> hashMap = new HashMap<>();
hashMap.put("Apple", 3);
hashMap.put("Banana", 5);
hashMap.put("Cherry", 1);
System.out.println(hashMap.containsKey("Cherry")); // 출력: true
System.out.println(hashMap.containsValue(4)); // 출력: false
- size(): Map에 저장된 항목의 개수를 보여준다.
HashMap<String, Integer> hashMap = new HashMap<>();
hashMap.put("Apple", 3);
hashMap.put("Banana", 5);
hashMap.put("Cherry", 1);
System.out.println(hashMap.isEmpty()); // 출력: false
3. 트리맵(TreeMap)
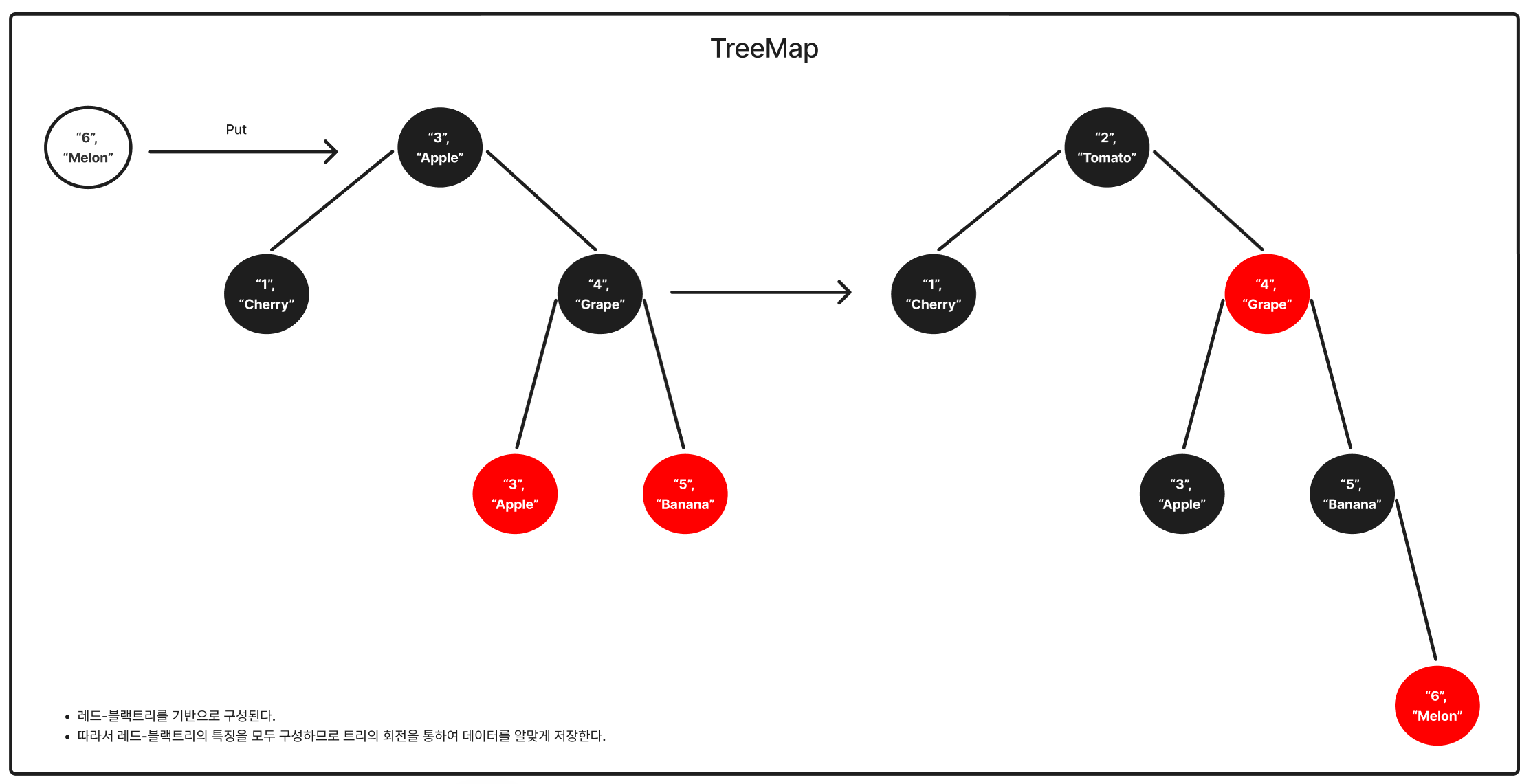
- 트리맵은 내부적으로 이진 탐색 트리(보통 레드-블랙 트리)를 사용하여 데이터를 정렬된 순서로 관리한다.
- 키의 자연 순서 또는 지정된 Comparator에 따라 항상 정렬된 상태를 유지한다.
- 평균적으로 삽입/삭제/검색 연산이 O(logN)의 시간복잡도를 가진다.
- null을 허용하지 않는다.
- 정렬이 되어있어 특정 범위의 키에 대한 검색이나 순회가 용이하다.
3-1. 트리맵 주요 메소드
- put(K key, V value): HashMap과 마찬가지로 키와 값을 저장하지만 항상 정렬된 순서를 유지합니다.'
TreeMap<String, Integer> treeMap = new TreeMap<>();
treeMap.put("Apple", 3);
treeMap.put("Banana", 5);
treeMap.put("Cherry", 1);
- get(Object key): 주어진 키의 대응하는 값을 반환한다.
TreeMap<String, Integer> treeMap = new TreeMap<>();
treeMap.put("Apple", 3);
treeMap.put("Banana", 5);
treeMap.put("Cherry", 1);
System.out.println(treeMap.get("Apple")); // 출력: 3
- remove(Object key): 특정 키와 연결된 값을 삭제하고 반환한다.
TreeMap<String, Integer> treeMap = new TreeMap<>();
treeMap.put("Apple", 3);
treeMap.put("Banana", 5);
treeMap.put("Cherry", 1);
System.out.println(treeMap.remove("Banana")); // 출력: 5
- firstKey(): 정렬된 순서에서 가장 작은 키를 반환한다.
TreeMap<String, Integer> treeMap = new TreeMap<>();
treeMap.put("Apple", 3);
treeMap.put("Banana", 5);
treeMap.put("Cherry", 1);
System.out.println(treeMap.firstKey()); // 출력: "Apple"
- lastKey(): 정렬된 순서에서 가장 큰 키를 반환한다.
TreeMap<String, Integer> treeMap = new TreeMap<>();
treeMap.put("Apple", 3);
treeMap.put("Banana", 5);
treeMap.put("Cherry", 1);
System.out.println(treeMap.lastKey()); // 출력: "Cherry"
- subMap(K fromKey, K toKey): 주어진 범위의 키를 포함하는 부분 Map을 반환한다.
TreeMap<String, Integer> treeMap = new TreeMap<>();
treeMap.put("Apple", 3);
treeMap.put("Banana", 5);
treeMap.put("Cherry", 1);
System.out.println(treeMap.subMap("Apple", "Cherry")); // 출력: {Apple=3, Banana=5}
4. 활용 알고리즘
4-1. 빈도수 카운팅
- 문자열 배열에 있는 요소들의 빈도수를 계산하여 몇 번 등장하는지 구하는 알고리즘이다.
public class FrequencyCounter {
public static void main(String[] args) {
// 예제 데이터
String[] fruits = {"Apple", "Banana", "Cherry", "Apple", "Banana", "Apple"};
// HashMap을 이용해 각 과일의 빈도수를 저장
Map<String, Integer> frequencyMap = new HashMap<>();
for(String fruit : fruits) {
// 기존 빈도수를 가져와 더하기
frequencyMap.put(fruit, frequencyMap.getOrDefault(fruit, 0) + 1);
}
// 출력: {Apple=3, Banana=2, Cherry=1}
System.out.println(frequencyMap);
}
}
4-2. 애너그램 그룹화
- 여러 문자열이 주어졌을 때, 서로 애너그램(같은 문자들로 구성되어 순서만 다른 문자열)인 것끼리 그룹화하는 알고리즘
public class GroupAnagrams {
public static void main(String[] args) {
// 예제 데이터
String[] word = {"eat", "tea", "tan", "ate", "nat", "bat"};
// 애너그램 그룹을 저장할 HashMap: 정렬된 문자열 -> 해당 애너그램 그룹
Map<String, List<String>> anagramMap = new HashMap<>();
// 각 문자열 처리
for(String word : words) {
// 문자열을 문자 배열로 변환 후 정렬
char[] charArray = word.toCharArray();
Arrays.sort(charArray);
String key = new String(charArray);
// key가 존재하지 않으면 새 리스트 생성
if(!anagramMap.containsKey(key)) {
anagramMap.put(key, new ArrayList<>());
}
// 해당 그룹에 단어 추가
anagramMap.get(key).add(word);
}
// 출력 : [eat, tea, ate], [tan, nat], [bat]
for (List<String> group : anagramMap.values()) {
System.out.println(group);
}
}
}


